OpenAI 影像生成
使用 OpenAI 的影像模型生成圖像——與 ChatGPT 內部驅動影像生成的同一家族,現已導入 VidOne 工作流程。
OpenAI 的影像模型——強大的指令遵循能力、在畫面內渲染設計級文字,並為你真正寫下的任務交付乾淨的編輯級成品。
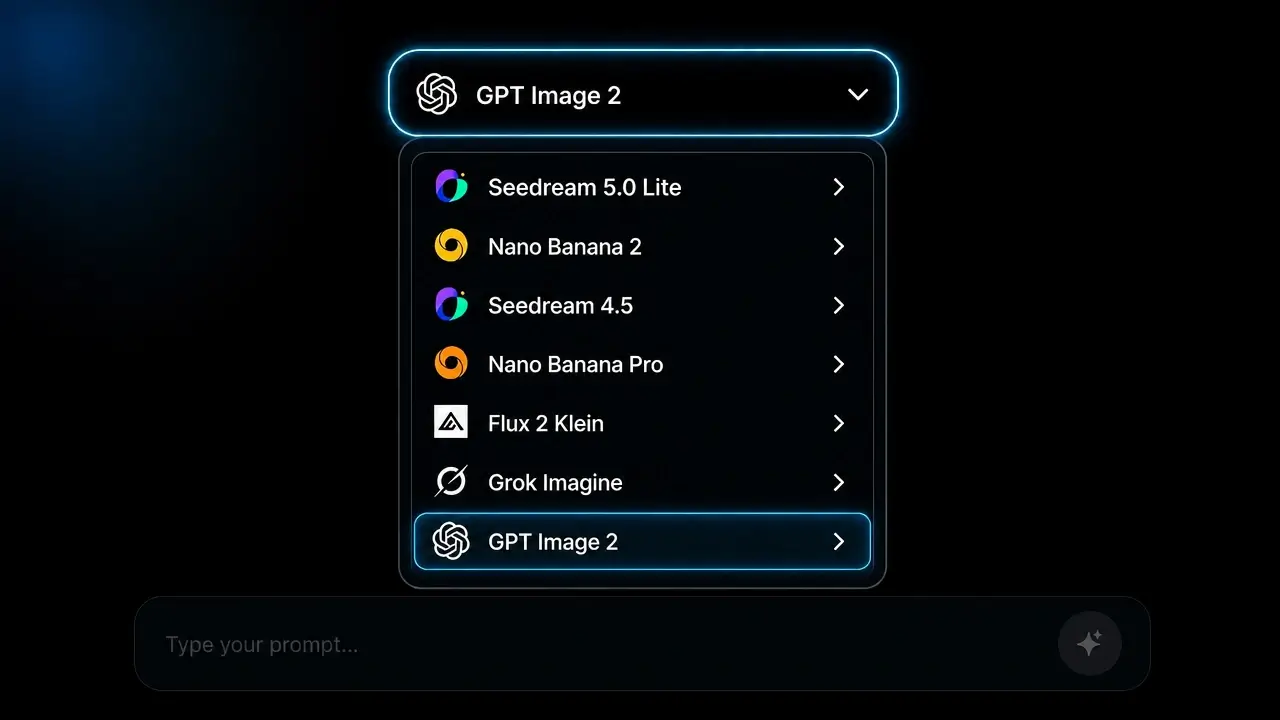
從影像模型選單中挑選 GPT Image 2。可在 OpenAI、Google Nano Banana、BytePlus Seedream 與 Black Forest Labs Flux 之間一鍵切換,無需離開頁面。

描述主體、場景、風格,以及任何文字或限制條件。GPT Image 2 會緊密遵循多段指令——列出畫面中應該出現什麼、不應該出現什麼,以及希望呈現的調性。
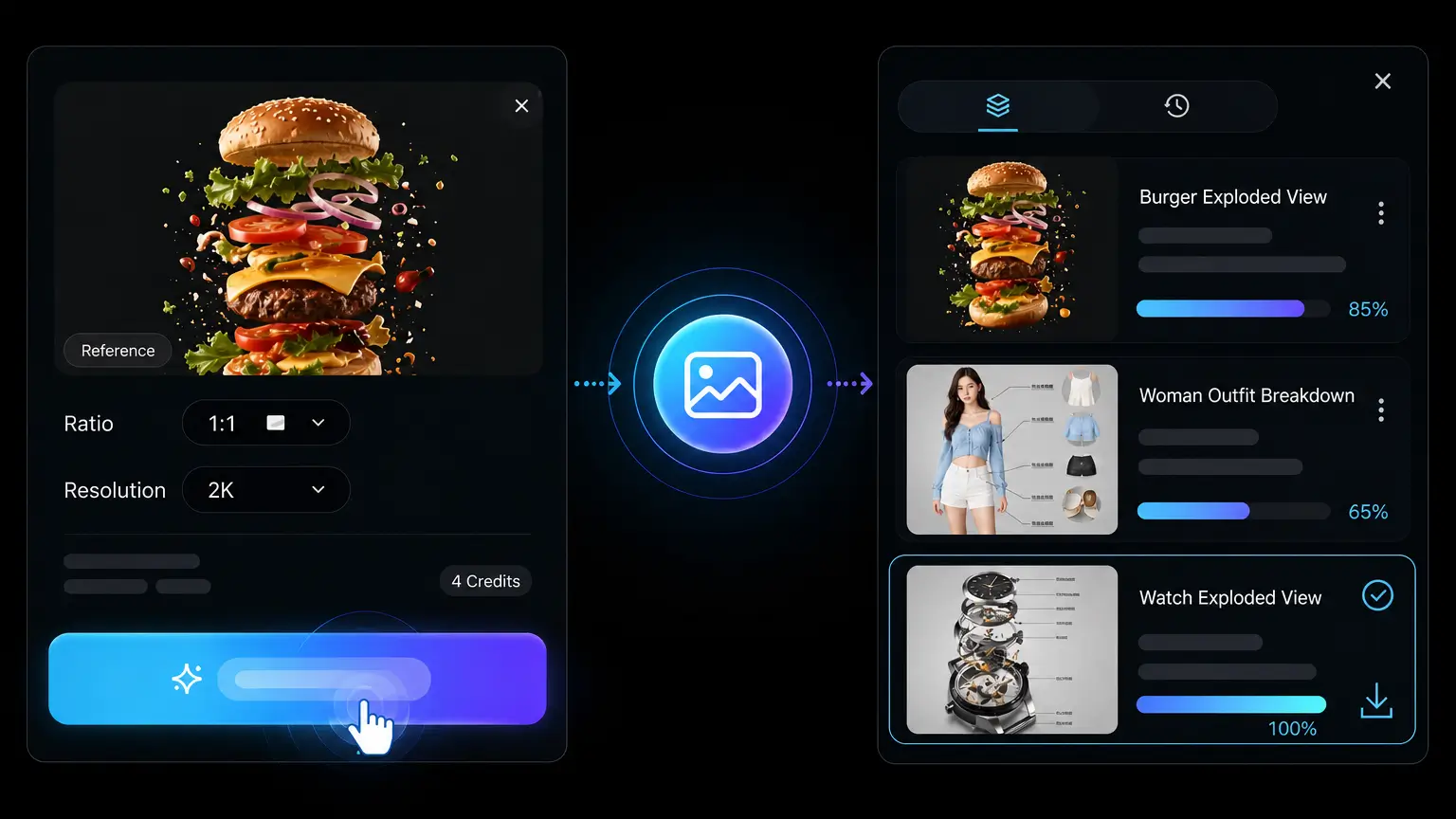
以標準或 HD 解析度渲染,支援方形、橫式與直式比例,再下載 PNG——可直接用於貼文、廣告、部落格標頭與產品頁。
GPT Image 2 是 OpenAI 全新的圖像生成體驗。它把圖像創作與編輯整合進對話式工作流,你只需描述想要的畫面,再用後續指令逐步精修結果即可。

使用 GPT Image 2 製作插畫、行銷概念、產品場景、海報、社群圖、分鏡圖以及其他視覺草稿。可以從文字提示開始,提供參考圖,或要求對現有圖像進行編修。生成結果可以作為獨立素材使用,也可以成為在 VidOne 製作影片的起點。
從靈感到可用的視覺成品,不必在多個工具間來回切換。VidOne 提供一個對話式的環境讓你生成、檢視並打磨圖像,再順勢進入更廣的內容創作流程。

描述你想看到的主體、場景、構圖、氛圍與視覺風格。GPT Image 2 會把這些指令整合理解,幫你從粗略概念走到清晰的視覺方向。對於需要先探索行銷概念、故事分鏡或品牌素材再進入正式製作的創作者與行銷人來說,特別實用。

用日常語言下達精準的修改指令,不必整張圖重新生成。你可以說明要調整的元素、想要的結果,以及哪些部分要保留。這種對話式編修讓你能輕鬆嘗試不同背景、配色、佈局或細節,同時始終看得到原本的創意走向。
當文字無法精準表達你想要的外觀、角色、商品或構圖時,上傳一張參考圖。參考圖給模型一個視覺起點,你的提示則說明哪些保留、哪些變換。這讓團隊能探索新場景與變體,又不會丟掉原圖最關鍵的識別特徵。

把第一次生成的結果當作草稿,而不是最終答案。接著繼續對話,調整構圖、修正細節、簡化畫面或嘗試新處理。這種反覆精修讓創意決策始終由你掌控,由模型負責執行,不必事先寫出一個無比龐大的提示詞。
出色的圖像生成不只是產出一張好看的圖。重點在於主導那些細節,讓視覺真正能服務於某個活動、故事、產品或受眾。

為海報、書封、菜單、包裝、社群圖等以文字為構圖一部分的內容打造概念。在提示中明確指定文案內容、位置、層級與周邊設計。清晰的指令讓你更快探索版面,縮短從視覺構想到設計師可繼續打磨素材之間的差距。

用參考圖與重複的創意指令,引導角色、商品、配色與氛圍在多張相關圖像中保持一致。當你在做一整組內容而不只是單張貼文時,視覺方向的連貫性格外重要。把關鍵細節延續下去,你就能發展出彼此呼應的分鏡、活動變體與場景概念,而不是看起來像隨機生成的素材。

當大部分畫面都符合預期時,只需要描述需要調整的那一塊。指定要更改的物件、表情、背景元素、燈光或某段文字,同時保留整體構圖。聚焦的編修能守住你已經滿意的決策,縮短修稿循環,讓嘗試變得更有目的,而不是被輕易丟棄。
GPT Image 2 既能支援快速發想,也能勝任更結構化的製作流程。先從受眾真正需要的格式出發,再圍繞訊息、渠道與下一步創作環節去塑造這張圖。

為上線貼文、活動公告、付費廣告以及各渠道專屬活動發想視覺方向。在提示中明確指定目標平台、長寬比、標題、主視覺主體與品牌氛圍。行銷人員可以快速比較幾個概念、選定方向、進一步打磨,再把通過的版本擴展成一整套行銷素材。
OpenAI 的影像模型——專為有限制條件的規格驅動創意工作而打造,產出必須忠實實現任務需求。
使用 OpenAI 的影像模型生成圖像——與 ChatGPT 內部驅動影像生成的同一家族,現已導入 VidOne 工作流程。
包含多項必備元素與明確限制的複合任務簡報,會被忠實實現而非簡化處理。
海報、包裝、招牌與 UI 畫面,皆能以清晰且拼寫正確的設計級文字呈現——是通用影像模型中最強的畫內文字能力之一。
強大的預設構圖與光線——畫面看起來像經過美術指導,卻無需詳細指示。適合封面靜幀、雜誌場景與品牌視覺。
可渲染 1:1、16:9、9:16、4:3 與 3:4——直接適用於貼文、橫幅、直式短片、部落格標頭與廣告版位,無需重新裁切。
OpenAI 的安全與審核政策適用於每一次渲染——專為合法的品牌、編輯與創作者使用情境而打造。
影片與圖片生成一站式平台 — Veo、Sora、Kling、Seedance、Wan、Grok 等更多模型。
GPT Image 2 是 OpenAI 的影像生成模型。它能忠實實現多段指令、在畫面內乾淨地渲染設計級文字,並預設輸出具備編輯級構圖與光線——當任務簡報有需要被尊重的限制條件時,就選它。
還有其他問題? 聯繫客服團隊






