OpenAI 画像生成
OpenAI の画像モデルで画像を生成 — ChatGPT 内の画像生成を支えるのと同じファミリーが VidOne ワークフローに登場。
OpenAI の画像モデル — 強い指示追従、画面内に配置されたデザインテキスト、あなたが実際に書いたブリーフに応えるクリーンなエディトリアル出力。
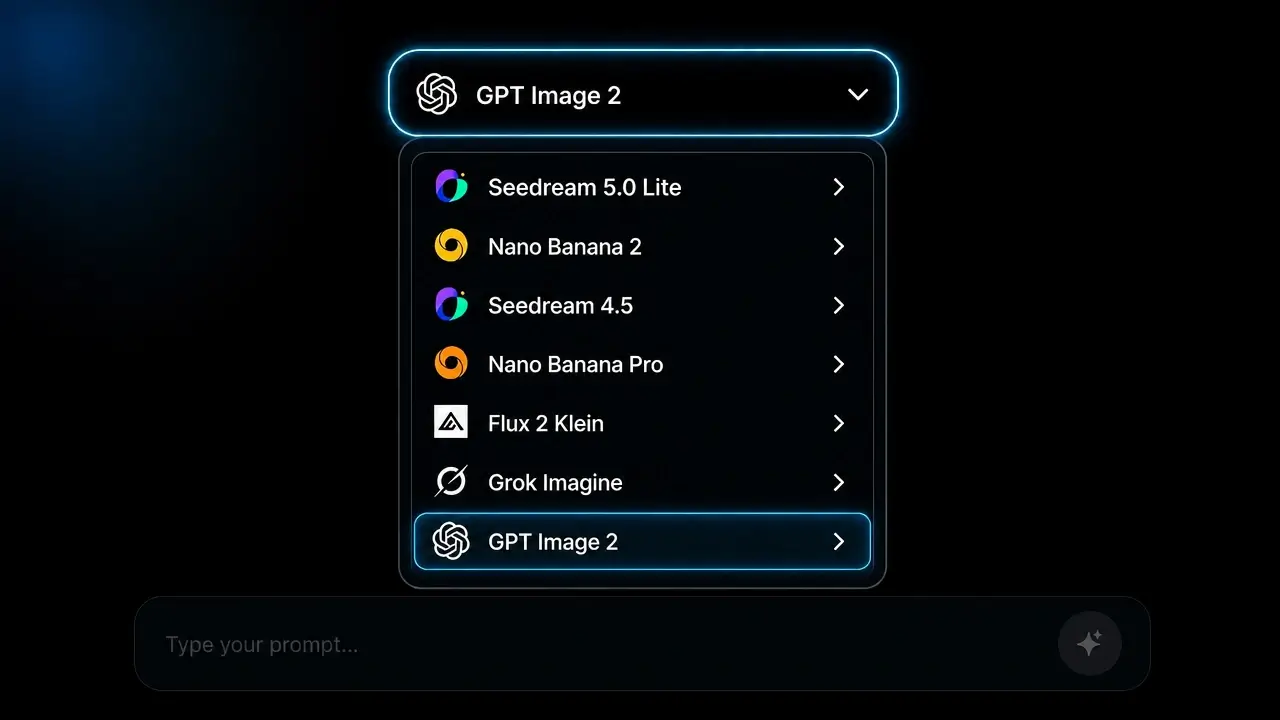
画像モデルメニューから GPT Image 2 を選びます。ページを離れることなく OpenAI、Google Nano Banana、BytePlus Seedream、Black Forest Labs Flux を切り替えられます。

被写体、シーン、スタイル、テキストや制約を記述します。GPT Image 2 はマルチパート指示を忠実に追従します — 画面に何を入れるか、何を入れないか、どんなトーンを狙うかを並べてください。
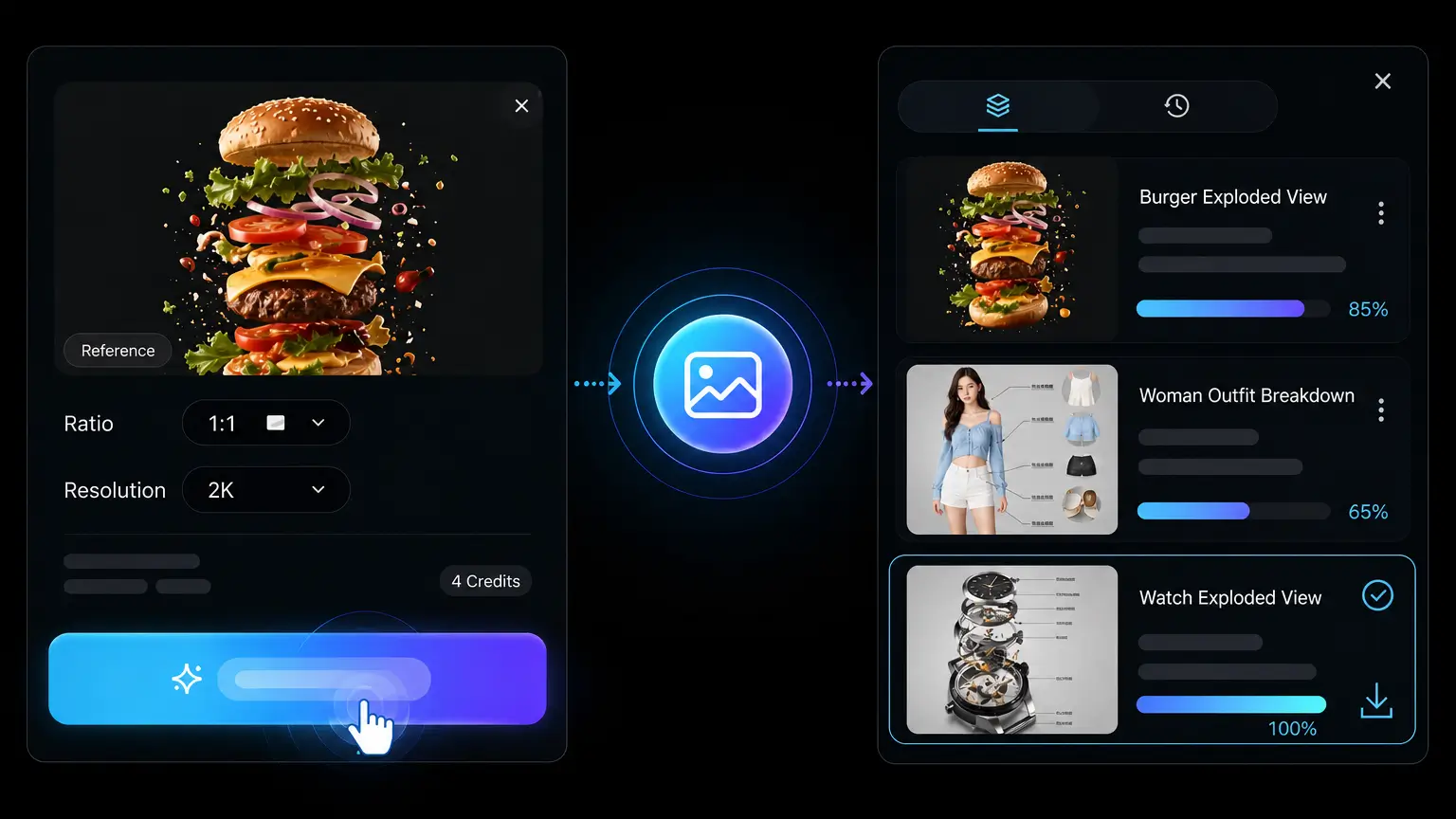
スタンダードまたは HD 解像度で正方形・横長・縦長のアスペクト比でレンダリング、PNG をダウンロード — 投稿、広告、ブログヘッダー、商品ページに公開準備完了です。
GPT Image 2 は OpenAI の最新の画像生成体験です。画像の作成と編集を会話型のワークフローに統合しているので、欲しいイメージを言葉で伝え、追加の指示で結果を磨き込めます。

GPT Image 2 はイラスト、キャンペーンのコンセプト、プロダクトシーン、ポスター、ソーシャル用ビジュアル、絵コンテなど、あらゆる視覚ドラフトに活用できます。テキストプロンプトから始めても、参考画像を渡しても、既存画像の編集を依頼してもかまいません。出力はそのまま素材として使うことも、VidOne で動画を作る出発点にすることもできます。
最初のアイデアから使える視覚素材まで、別々のツールを行き来して流れを途切れさせる必要はありません。VidOne なら会話の中で生成・確認・調整までを一貫して行え、その先のコンテンツ制作へとスムーズに進めます。

見たい被写体、シーン、構図、ムード、ビジュアルスタイルを言葉で伝えてください。GPT Image 2 はそれらの指示をまとめて解釈し、ぼんやりしたアイデアから明確なビジュアルの方向性へ導きます。本制作に入る前に、キャンペーンの案、ストーリーの分割カット、ブランドのコンセプトを試したいクリエイターやマーケターに特に有効です。

画像全体を手作業で作り直すのではなく、普段の言葉でピンポイントの修正を依頼できます。調整したい要素、望む結果、変えたくない部分を伝えるだけで OK。この会話型の編集フローなら、元の方向性を見失わずに別の背景、配色、レイアウト、ディテールを気軽に試せます。
ルック、キャラクター、商品、構図を言葉だけでは伝えきれない時は、リファレンス画像をアップロードしてください。リファレンスはモデルに視覚的な出発点を与え、プロンプトでは何を残し何を変えるかを補足します。これによりチームは、元画像の見覚えのある特徴を保ちつつ新しいシーンやバリエーションを探れます。

最初の生成は最終回答ではなく、ドラフトとして扱いましょう。会話を続けて構図を改善し、ディテールを修正し、シーンを整理し、新しい処理を試せます。反復的なリファインによりクリエイティブの判断は手元に残り、実行はモデルが担当 — 最初から巨大なプロンプトを書かなくても、より強い結果に到達できます。
優れた画像生成とは、ただ魅力的な絵を出すことではありません。実際のキャンペーン、ストーリー、プロダクト、オーディエンスに本当に役立つビジュアルになるよう、ディテールを意図的に方向づけることです。

ポスター、表紙、メニュー、パッケージ、ソーシャル用グラフィックなど、文字が構図の一部となるコンセプトを制作できます。コピーの文言、配置、階層、まわりのデザインをプロンプトで具体的に指定してください。明確な指示があれば、レイアウトを素早く試せ、ビジュアルのアイデアからデザイナーが仕上げられるアセットまでの距離が縮まります。

リファレンスと繰り返しのクリエイティブ指示を使い、関連する画像群でキャラクター、商品、配色、世界観を導きましょう。一本の投稿ではなく一連のコンテンツを作るときは、方向性の一貫性が重要です。鍵となるディテールを引き継いでいけば、ランダムに生成されたものではなく、つながりのあるストーリーボード、キャンペーンのバリエーション、シーンコンセプトを育てられます。

大半がうまく行っているなら、手を入れたい部分だけを言葉で伝えてください。物体、表情、背景要素、ライティング、テキストの一部だけを変えて、全体の構図はそのまま保てます。フォーカスした編集は、すでに気に入っている判断を守り、リバイズの周回を短くし、試行を使い捨てではなく意図的なものに変えてくれます。
GPT Image 2 はサッと発想する場面でも、もう少し構造化された制作でも力を発揮します。まずオーディエンスに必要なフォーマットから入り、メッセージ、配信チャネル、そして次のクリエイティブ工程に向けて画像をかたちづくっていきましょう。

ローンチ投稿、イベント告知、ペイド広告、チャネル別キャンペーンのビジュアル方向性を組み立てます。プロンプトには、想定プラットフォーム、アスペクト比、見出し、主役の被写体、ブランドのムードを含めてください。マーケターは複数のコンセプトを素早く比較し、方向性を選び、洗練させたうえで、承認版を一連のキャンペーン素材へと展開できます。
OpenAI の画像モデル — ブリーフに制約があり、出力がそれを尊重する必要があるスペック駆動のクリエイティブワークのために構築されました。
OpenAI の画像モデルで画像を生成 — ChatGPT 内の画像生成を支えるのと同じファミリーが VidOne ワークフローに登場。
複数の必須要素と明示的な制約を含む複合ブリーフが、簡略化されることなく尊重されて返ってきます。
ポスター、パッケージ、サイネージ、UI 画面が、読みやすく正しいスペルのデザインテキストでレンダリングされます — 一般画像モデルの中でも最強クラスの画面内テキスト能力です。
強力なデフォルト構図とライティング — 詳細な指示なしでもアートディレクションされたように見えるフレーム。表紙静止画、雑誌シーン、ブランドビジュアルに有効です。
1:1、16:9、9:16、4:3、3:4 で出力 — 再クロップなしで投稿、バナー、縦型ストーリー、ブログヘッダー、広告枠に対応。
OpenAI のセーフティとモデレーションポリシーがすべてのレンダリングに適用 — 正当なブランド、エディトリアル、クリエイター用途のために構築されています。
動画と画像生成を一つのプラットフォームで — Veo、Sora、Kling、Seedance、Wan、Grokなど。
GPT Image 2 は OpenAI の画像生成モデルです。マルチクローズな指示を尊重し、画面内のデザインテキストをクリーンにレンダリングし、デフォルトでエディトリアル品質の構図とライティングを生み出します — ブリーフに尊重すべき制約があるときに頼れるモデルです。
他にご質問はありますか? サポートチームにお問い合わせ






